Maximize LLM performance with
Arfniia Router, powered by online Reinforcement LearningArfniia Router is a customizable and production-ready LLM routing learning and serving API, designed to optimize LLM performance for your data, policies, and feedback signals, with adaptive learning capabilities and flexible BYOC deployment.
Discover the Advantages
Deploy via BYOC, ensuring all data stays entirely within your infrastructure and chosen LLM providers, with no third-party access.
Maximize LLM performance by leveraging business context and feedback, integrating the best capabilities of multiple LLMs.
Decode decisions across multi-stage feature engineering, policy learning, exploration, and priors, to show why each model is chosen.
Customize routing criteria to prioritize business-specific KPIs aligned with ROI, such as RAG accuracy or AI agent success rates.
Apply the power of online Reinforcement Learning, minimizing retraining while continuously improving performance.
Guarantee adherence to LLM provider terms, excluding their outputs from our learning process and maintaining full compliance.
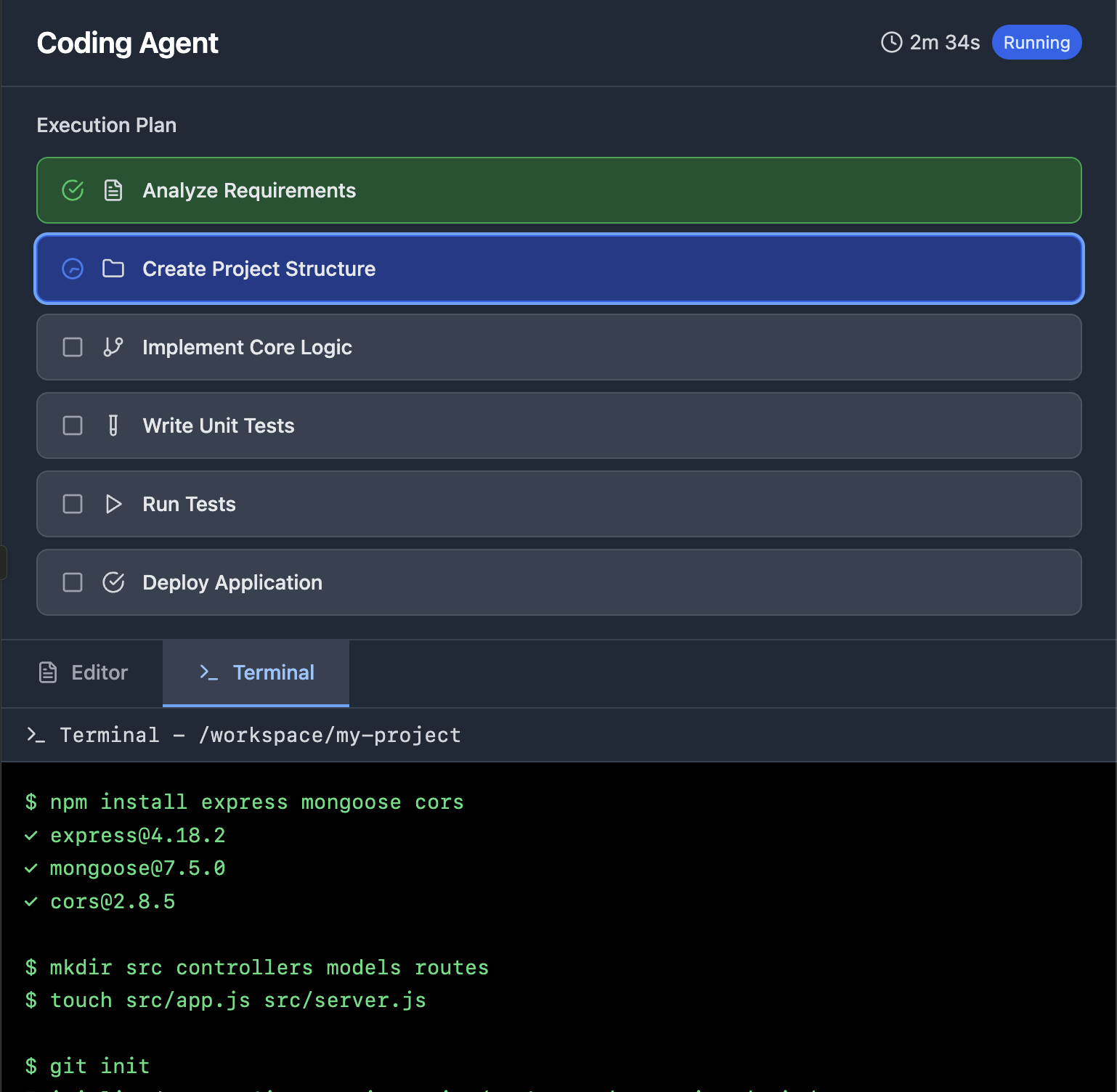
Inside the Router
A quick walkthrough of how Arfniia routes each request.
Step 1: Enhance Context
The router receives the prompt plus metadata and constructs contextual features for decision-making.
Step 2: Build Action Space
Filters available models by policy, past performance, and provider status to form a dynamic action space.
Step 3: Score, Explore, and Route
A learned policy scores candidates against KPIs, with exploration, then selects the model expected to perform best.
Step 4: Collect Feedbacks & Learn
Aggregated KPI and optional per-request feedback update the online RL policy, balancing quality and cost per your weights.
Use Cases
Systematically select the best model for each task. Arfniia routes every request to the optimal model based on your defined KPIs.
Marketing
Drive Core Metrics
Whether your goal is lead generation, user engagement, or sales conversions, Arfniia continuously learns from performance data to prioritize the models that deliver the best results.
Adapt to Evolving Objectives
As business objectives evolve, from acquisition to retention, Arfniia adapts. Just update your core optimization goal, and the router adjusts its policy in real-time to align with the new KPI.
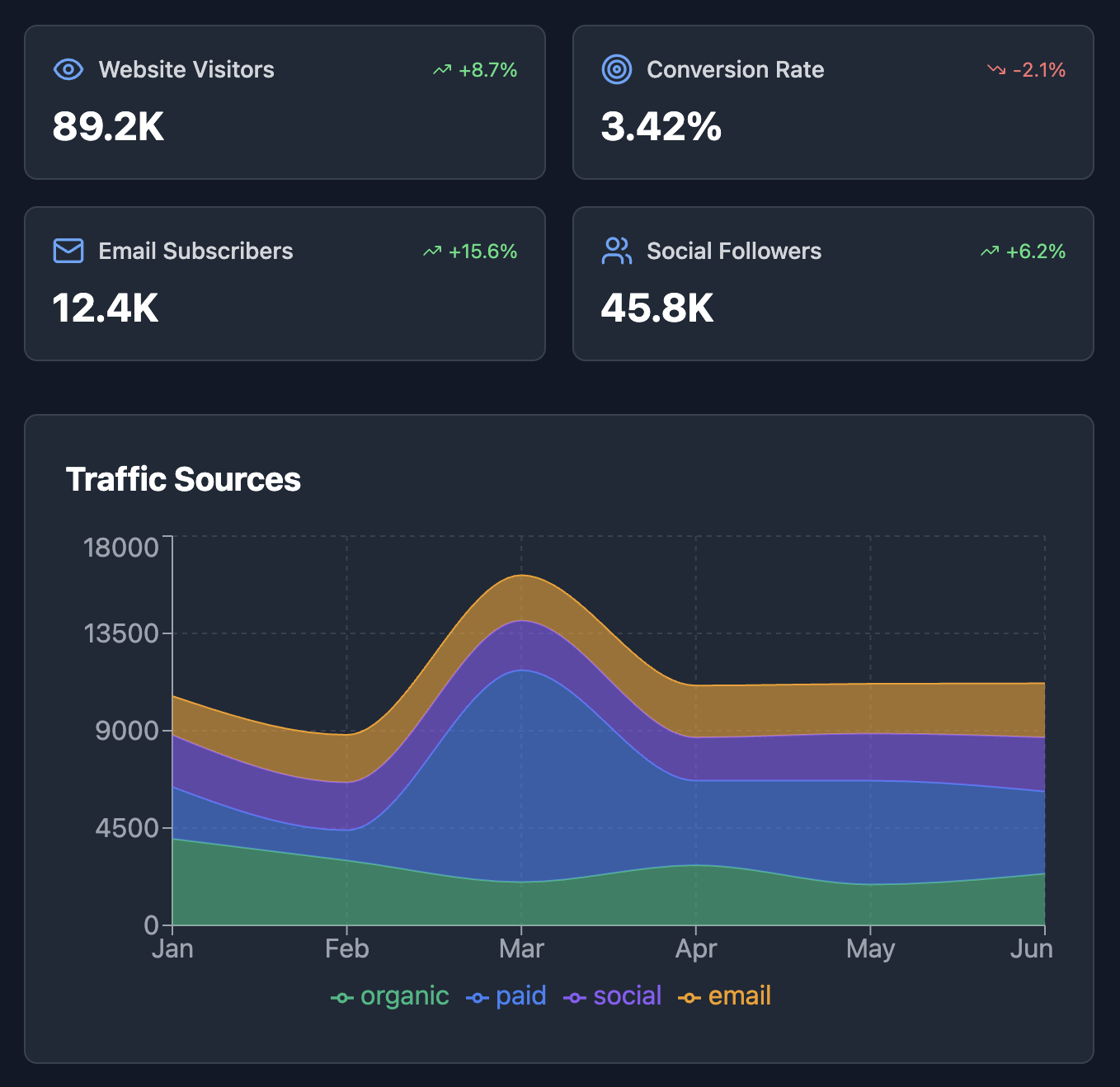
Coding
Always Up-To-Date LLMs
Arfniia treats the set of available models as a dynamic action space. New models or variants can be added without retraining the system, and the router can incorporate them into decision-making immediately.
Combined Model Capabilities
Even models from the same family can differ in capabilities. Arfniia combines their strengths by learning where each model performs best, effectively leveraging the union of performance rather than relying on a single option.
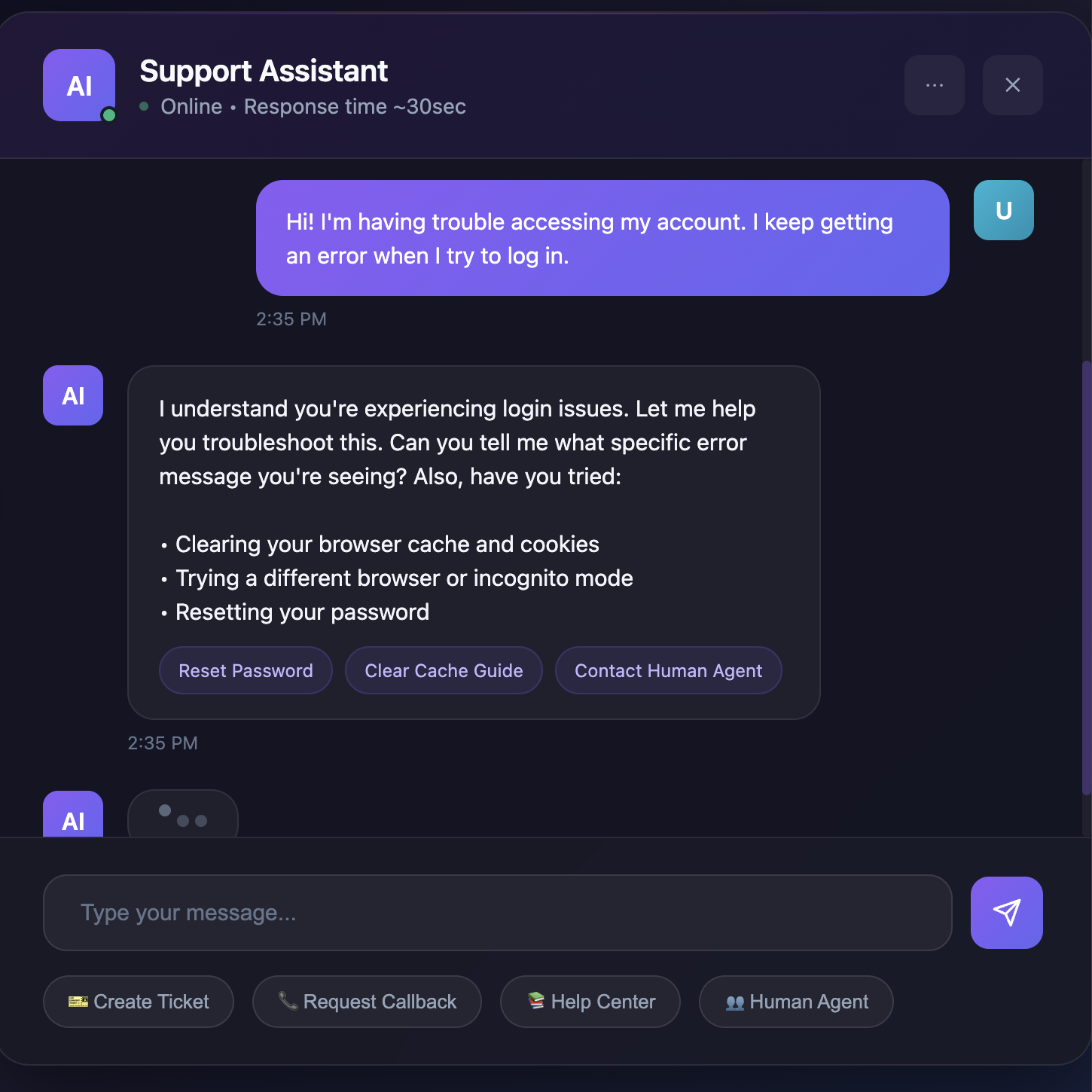
Customer Service
Resolution Rate Optimization
Episodic, multi-turn learning routes each step to the right model, fast, low-cost for FAQs, stronger reasoning for edge cases, improving first-contact resolution and reducing time-to-resolution.
Personalized Experience
Adapts to user preferences in-session: tone, verbosity, and channel. The router learns from ongoing interactions to select models that match customer style while meeting cost and policy constraints.
Performance Metrics
SWE-bench Verified
Frequently Asked Questions
What's the meaning of Arfniia?
Arfniia is a palindrome of "AIInfra", symbolizing the idea of "Working Backwards" for AI infrastructure.
What is feedback, and why do I need it?
Reinforcement Learning relies on feedback loops to improve. In our system, business KPIs serve as the ultimate "feedback" for LLM routing decisions. We provide a /v1/feedbacks API to adjust the policy at runtime, users can submit delayed/sparse feedback periodically or immediate feedback for each prompt/completion, or both. For more API details, please refer to the /docs endpoint.
Can I optimize cost?
Absolutely, while cost savings are a natural result of any routing algorithm, you can also fine-tune the feedback_cost_weights parameter to adjust the final reward, for example, [0.5, 0.5] assigns equal weight to both feedback and cost.
Which Reinforcement Learning algorithm do you use?
We utilize a custom hybrid RL approach that combines both on-policy and off-policy techniques, designed for stability, learning efficiency, and to be compute-friendly. We'll share more details about our design choices in an upcoming blog post. Stay tuned!
Arfniia Router for Amazon Bedrock
Maximize LLM performance with seamless and efficient LLM routing